Biography
Hi, I’m Zeyu, a doctoral researcher at KU Leuven, supervised by Prof. Andrew Vande Moere in the Research[x]Design group. My research interests include Human-Computer Interaction, Digital Humanities, Cultural Heritage, Generative AI, Accessibility, and Computer Music.
My doctoral work is part of the Multimodal Human–AI Interaction for Curiosity-Driven Discovery in the Digital Humanities project, where I study how generative AI can help humanities scholars uncover unexpected connections across heterogeneous cultural collections. I’m also part of the Living Corpora: Pioneering human-AI collaboration in digital humanities project, which reimagines generative AI as an intellectual partner for humanities research through explainable, collaborative, adaptive, and responsible AI systems.
Download my CV.
- Human-Computer Interaction
- VR/AR/MR
- Cultural Heritage
- Generative AI
- Accessibility
- Computer Music
-
PhD in Design Informatics, 2026 - present
KU Leuven
-
MPhil in Computational Media and Arts, 2024
The Hong Kong University of Science and Technology
-
BSc in Computer Science with Artificial Intelligence, 2022
University of Nottingham, Ningbo China
-
BSc in Computer Science with Artificial Intelligence, 2022
University of Nottingham
Skills
Experience
The Research[x]Design (rxd) group is at KU Leuven within the Faculty of Architecture. The group is led by Prof. Andrew Vande Moere.
My responsibilities include:
- Research at the intersection of HCI, Generative AI, Digital Humanities, and Cultural Heritage.
Lumo Tech is an interior design company building generative-AI-powered tools and workflows for designers and clients.
My responsibilities include:
- Leading technology strategy and product engineering
- Designing and building generative AI systems for interior design
The PEACH LAB is at ETH Zurich within the Department of Computer Science (D-INFK). The group is led by Prof. April Wang.
My responsibilities include:
- Research on various projects related to HCI (specifically focusing on AI literacy education)
- Manage various affairs of the lab as a core member.
The APEX research group is at The Hong Kong University of Science and Technology (Guangzhou) within the Computational Media and Arts Thrust and The Hong Kong University of Science and Technology within the Division of Integrative Systems and Design. The group is led by Prof. Mingming Fan.
My responsibilities include:
- Research on various projects related to HCI (specifically focusing on accessibility)
A Start-Up company focusing on Beauty Makeup Services Affiliated with the Ningbo Intelligent Technology Research Institute, which is founded by Ningbo government and prof. Zexiang Li at HKUST.
My responsibilities include:
- Managing
- Software Development (ios, android)
A Start-Up company focusing on building older adult’s life sharing & livestreaming platform. Team lead by Mr. Shenshen Li (Co-founder of Zhihu.com) and Mr. Qiangning Hong (formal Chief Architect of Douban.com).
My responsibilities include:
- Software Development (Web system, React.js)
An undergraduate on-campus research society with a particular focus on digital computing technology.
My responsibilities include:
- Managing
- Research on various projects related to Human-Vehicle Interaction
A Start-Up company focusing on students’ academic and life service.
My responsibilities include:
- Managing
- Software Development (WeChat Mini Program)
Accomplishments
Projects












Featured Publications


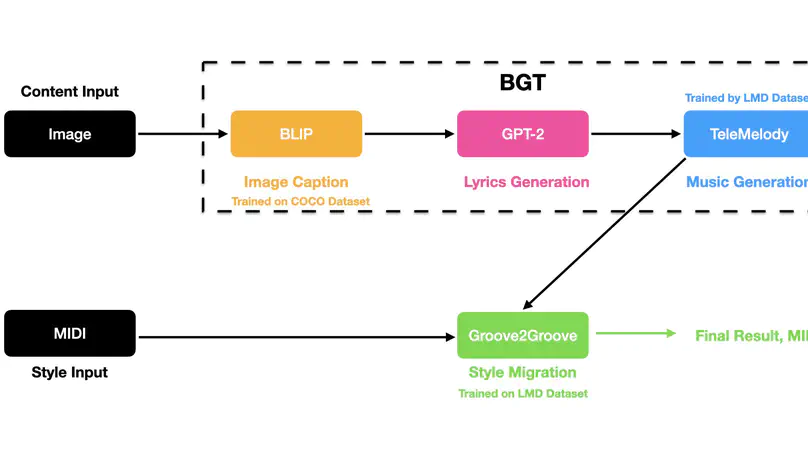
We propose a method for generating music from a given image through three stages of translation, from image to caption, caption to lyrics, and lyrics to instrumental music, which forms the content to be combined with a given style. We train our proposed model, which we call BGT (BLIP-GPT2-TeleMelody), on two open-source datasets, one containing over 200,000 labeled images, and another containing more than 175,000 MIDI music files. In contrast with pixel level translation, our system retains the semantics of the input image. We verify our claim through a user study in which participants were asked to match input images with generated music without access to the intermediate caption and lyrics. The results show that, while the matching rate among participants with little music expertise is essentially random, the rate among those with composition experience is significantly high, which strongly indicates that some semantic content of the input image is retained in the generated music. The source code is avaliable at https://github.com/BILLXZY1215/BGT-G2G.
Recent Publications
Contact
- zeyu.xiong@kuleuven.be
- Kasteelpark Arenburg 1 bus 2431, Heverlee, Flemish Brabant 3001