Abstract
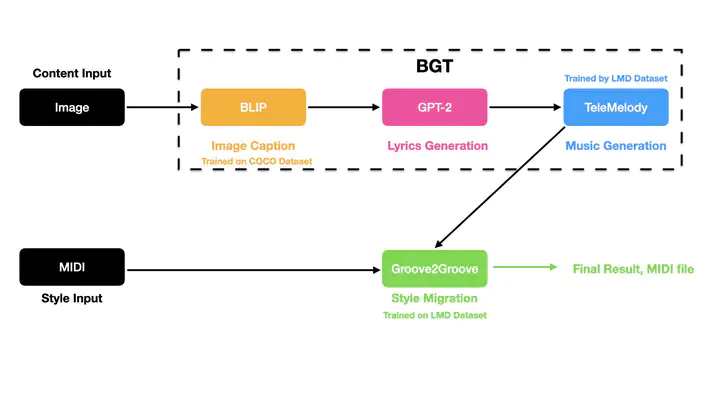
We propose a method for generating music from a given image through three stages of translation, from image to caption, caption to lyrics, and lyrics to instrumental music, which forms the content to be combined with a given style. We train our proposed model, which we call BGT (BLIP-GPT2-TeleMelody), on two open-source datasets, one containing over 200,000 labeled images, and another containing more than 175,000 MIDI music files. In contrast with pixel level translation, our system retains the semantics of the input image. We verify our claim through a user study in which participants were asked to match input images with generated music without access to the intermediate caption and lyrics. The results show that, while the matching rate among participants with little music expertise is essentially random, the rate among those with composition experience is significantly high, which strongly indicates that some semantic content of the input image is retained in the generated music. The source code is avaliable at https://github.com/BILLXZY1215/BGT-G2G.
Zeyu Xiong
Doctoral Researcher
My research interests include Human-Computer Interaction, VR/AR/MR, Cultural Heritage, Generative AI, Accessibility, and Computer Music.